Algorithm Time Complexity

When writing code it can seem inconsequential to add another if-else statement or loop because most of the code we write can terminate in seconds if not less. This is true for smaller projects that will be unused after their initial use. On a larger scale, certain code can be run billions of times making those inconsequential code snippets very detrimental to runtime. This is the study of time complexity or how long it takes for certain algorithms or tasks to run. The units here is not in terms of seconds or minutes but in time in terms of the size of the input and the functions used on it.
Let’s start very simple with the idea of finding the largest element in a unordered list. So let’s say we have a list of integers with a size of n that we are going to find the max value of. In order to find the max value in that list we must compare every element in the list with a place holder value that contains the largest element we have found so far. For now we can say that this operation of finding the largest element takes n steps because we need to compare the place holder to every one of the n elements in the list.
Another common task we perform as programmers is finding an element in an unordered list, or searching. There are many different ways to look through a list but let’s just think about binary search in which we start from the beginning and look at every element one by one until we find the one we are looking for. The interesting thing about this problem is that in the best case the element we are looking for is in the first position and we only need to check one location. In the worst case the element we are looking for is in the last position so we need to check all n elements.
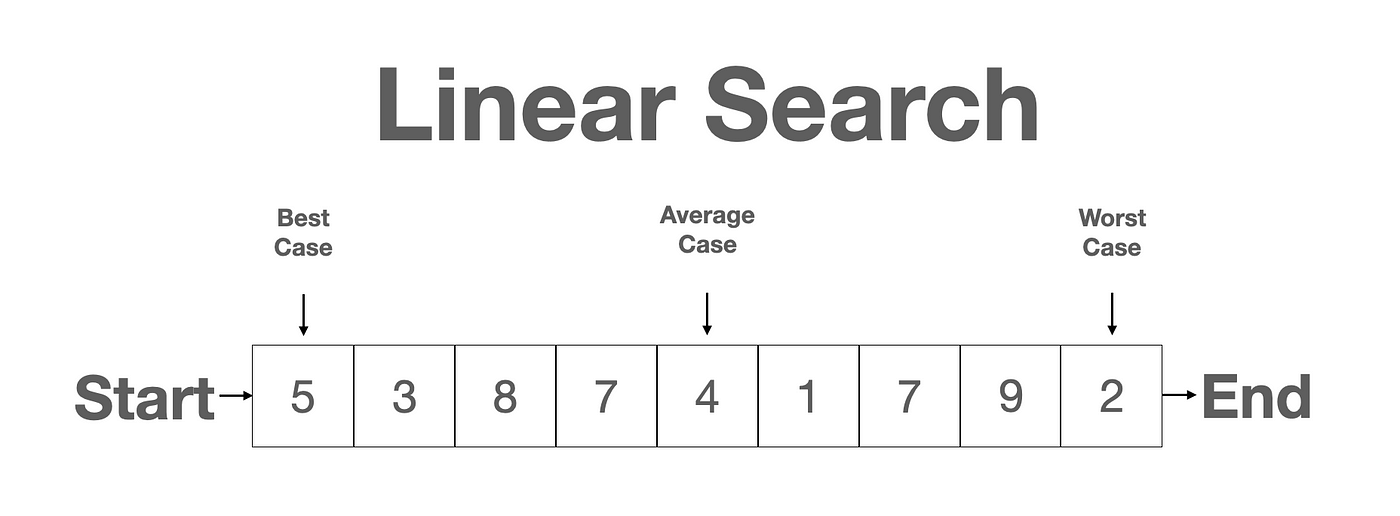
Best, Average, and Worst Case
In the world of computing we are able to assign a best case, average case, and worst case time complexity to evaluate the time it will take for an algorithm to run. These times are given in terms of n, n being the size of the object(s) that are we are using.
Want to read this story later? Save it in Journal.
Best Case (Big Omega Notation)
Going back to the example before of finding an element in a list. The best case is finding the value we want in the first item in the list, so we would say Ω(1). Omega (Ω) is used to represent best case time also called big omega notation. Best case is very rarely used because the best runtime can be due to some random phenomena that allowed algorithm to complete significantly faster than another iteration.
Average Case (Big Theta Notation)
The average case takes a bit more knowledge of how time complexity works but it ends up being Θ((n+1)/2), which boils down to Θ(n). Theta (Θ) is used to represent the average case, also being called big theta notation. Average case can be useful if we want an estimate of how long something will take to run but its accuracy will waver depending on the state of the input.
Worst Case (Big O Notation)
The worst case is finding the value at the end of the list, so we would say O(n). O (capital letter o) is used to represent the worst case, also called big O notation.
Big O Notation
The idea of worst case and best case are the root of time complexity and the evaluation of algorithms and how “long” they take to run. Big O notation is almost exclusively used because in a business context it is always better to give the worst case so that expectations are always met and projects are on/under budget. It is also used because of the ability to be sure the program will finish in an expected time.
But how do we find the time complexity for a given algorithm if it isn’t as simple as linear time? The first step is to identify the part of the process that has the fastest growing term in time complexity. For example if the time complexity is O(2n²+5n+1), the fastest growing would be 2n². Step two is to remove any coefficients, the end result being n². Here is an example in code:
Real Example
Lets say we want to find the product of a list of integers and write it as a function.That code would look like this:
The fastest growing term out of the 5 lines is O(n) because it scales with the size of the input. Then since there are no coefficients our final time complexity is O(n). Lets look at a more complicated example of finding the product of a list of lists (a matrix).
We can see that using our process this has a runtime of O(n²) because we need to iterate through n lists which each have a size of n.
Data Structures that are Fast
It may not seem like some data structures are faster at accessing elements than others but they are and there are good reasons for that. Lets say our goal is checking whether someone inputted the right password on a website. If we were to use a list it would be an O(n) operation looking for the tuple that contains the username/password pair. If we were to use a dictionary on the other hand, we could access any element in O(1) because of the ability to access the information we want by passing in a key. By using a key we only have to look at one location in memory to access the password.
What can we do with this knowledge in order to improve the runtimes of the code we write? There is no perfect answer to this but there are a lot of smaller things you can do to help the time of execution of the code.
- Be weary of unnecessary loops, list assignments, function calls, and other operations that can take large amount of time
- Algorithms like searching, sorting, etc. have been refined over time and there is usually a faster way to implement said algorithm (for example binary search instead of linear search or merge sort instead of bubble sort)
- Rethink the process that you performing and identify ways to rearrange processes in order to improve runtime
Extra Links:
More from Journal
There are many Black creators doing incredible work in Tech. This collection of resources shines a light on some of us:
